News
- 12/2024: 😇😇Start my PhD journey at the University of Trento, fighting step by step.
- 11/2024: 🎉🎉Finished my journey in BAAI. Great thanks to my advisors Zheng Liu and Bo Zhao.
- 12/2023: 😄😄Ended my RA at CAS. Great thanks to my advisor Yu Zhou.
- 06/2023: 🎉🎉Got my Master`s Degree at HIT. Great thanks to my advisor Shaohui Liu.
|
Research
I'm interested in computer vision, multimodal learning, video understanding, Remote Sensing and OCR. Below are some selected publications. (* indicates equal contribution.)
|
|
|
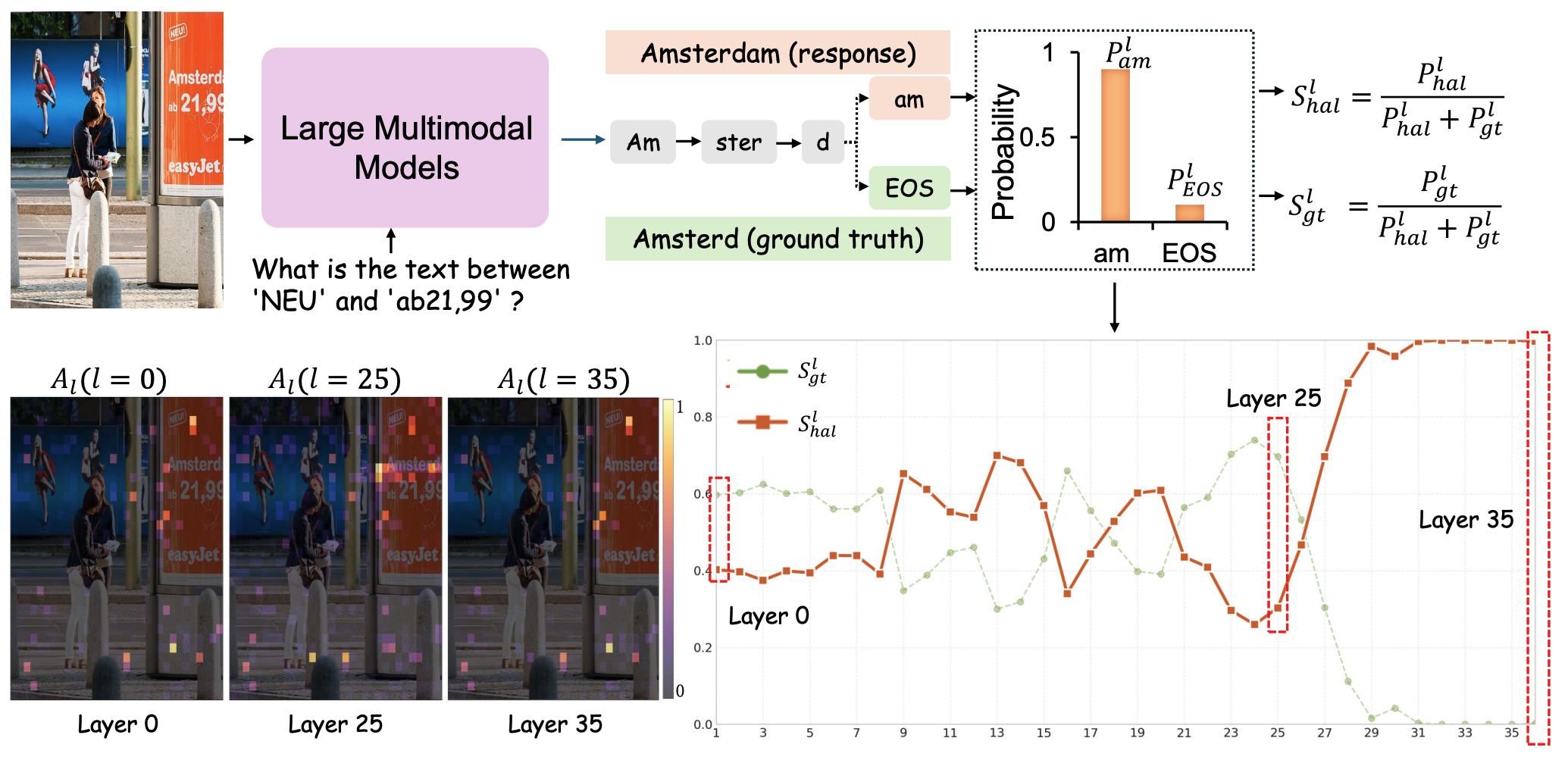
When Semantics Mislead Vision: Mitigating Large Multimodal Models Hallucinations in Scene Text Spotting and Understanding
Yan Shu*,
Hangui Lin*,
Yexin Liu*,
Yan Zhang,
Gangyan Zeng,
Yan Li,
Yu Zhou,
Ser-Nam Lim,
Harry Yang,
Nicu Sebe,
NeurIPS, 2025
project page /
Arxiv
Exploring and mitigating semantic hallucination in MLLMs.
|
|
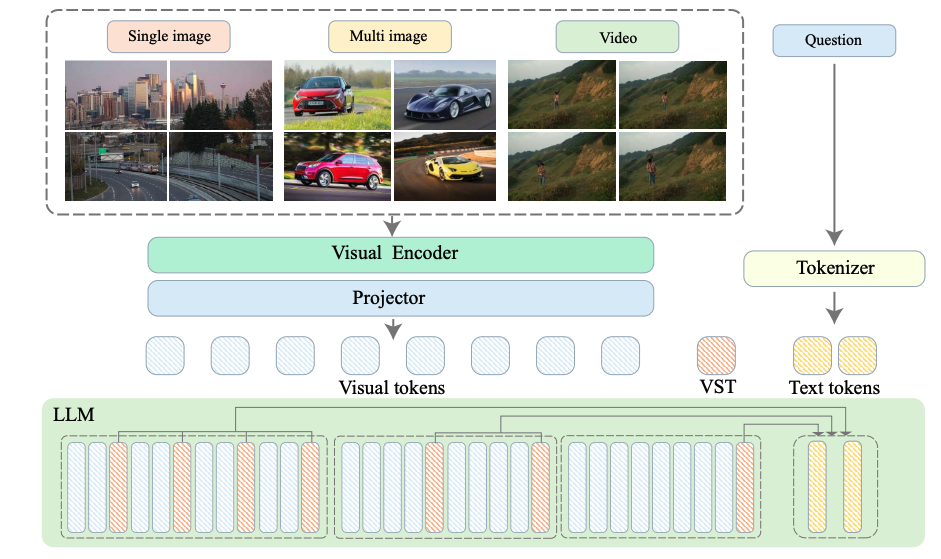
Video-XL: Extra-Long Vision Language Model for Hour-Scale Video Understanding
Yan Shu,
Peitian Zhang,
Zheng Liu,
Minghao Qin,
Junjie Zhou,
Tiejun Huang,
Bo Zhao
CVPR, 2025
(Oral)
project page /
Arxiv
First-ever hour-scale video understanding models.
|
|
|
MLVU: Multi-task Long Video Understanding Benchmark
Junjie Zhou*,
Yan Shu*,
Bo Zhao*,
Boya Wu,
Shitao Xiao,
Xi Yang,
Yongping Xiong,
Bo Zhang,
Tiejun Huang,
Zheng Liu
CVPR, 2025
project page /
Arxiv
First-ever comprehensive long video benchmark.
|
|
|
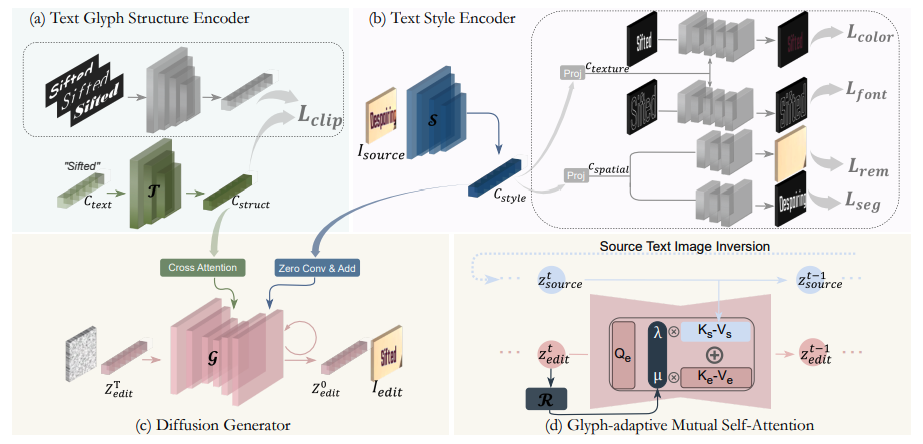
TextCtrl: Diffusion-based Scene Text Editing with Prior Guidance Control
Weichao Zeng,
Yan Shu,
Zhenhang Li,
Dongbao Yang,
Yu Zhou
NeurIPS, 2024
(Spotlight)
project page /
arXiv
A diffusion-based scene text editing model as well as a real-world scene text editing benchmark.
|
|
|
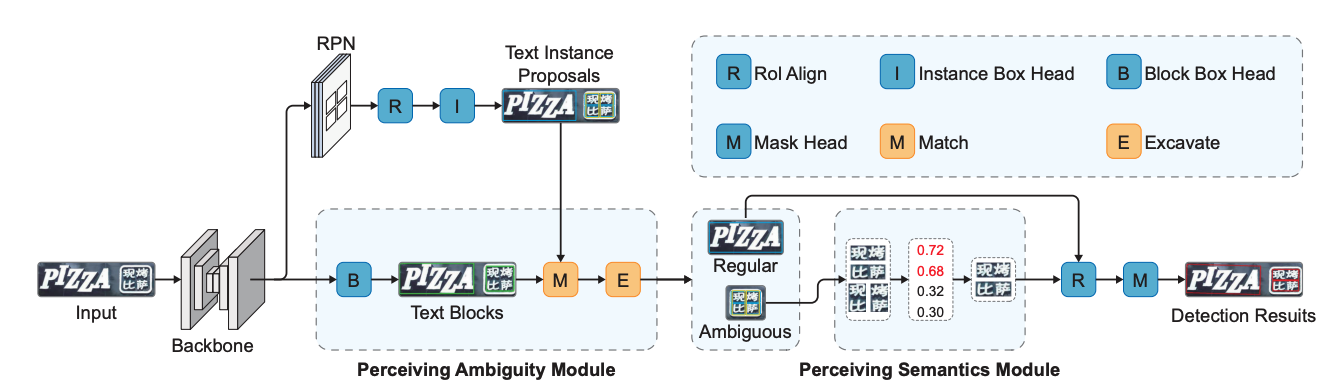
Perceiving Ambiguity and Semantics without Recognition: An Efficient and Effective Ambiguous Scene Text Detector
Yan Shu,
Wei Wang,
Yu Zhou,
Shaohui Liu,
Aoting Zhang,
Dongbao Yang,
Weiping Wang
ACM MM, 2023
(Oral)
project page /
arXiv
A model designed for ambiguous scene text detection.
|
Talks
- 12/2025: Give a talk about Semantic Halluciantion in MLLMs on CSIG(中国图像图形学会)
- 12/2024: Give a talk about Video-XL on 智源学者论坛
- 11/2024: Give a talk on Video LLMs at Renmin University invited by Prof. Ruihua Song
|
Education and Working Experience
|
|